In an economy, the standard categorization of assets is divisible and non-divisible. We could categorize all FIAT currencies, gold, land, etc., into divisible assets – everything we could divide into smaller chunks. On the other hand, a non-divisible asset is an asset that we can not divide legally – for example; we can not cut a piece from a painting and sell only it. The same is true for apartments, buildings, collectibles, etc. A unique number or id usually identifies both types of assets, but assets of non-divisible kinds sometimes could only have one copy.
We can see many parallels if we return to the crypto world and translate between the previous paragraph and the different tokens offered by the various crypto exchanges. In crypto, we call all divisible tokens “fungible”. Examples of such tokens are bitcoins, etheriums, and any other cryptocurrency. To verify transactions over the set of these tokens, we use the nature of how blockchain networks work. Every transaction is cryptographically signed, and one transaction keeps the metadata for the tokens transfer between two or more wallets. Usually, in this metadata, we store the unique id of the divisible token (when we split the token, we typically generate a new id/number for every part of the split).
You can see how financial people distinguish the fungible and non-fungible tokens/assets on the diagram. The non-fungible is usually a unique piece of art or collectible
The programming logic used to implement the described set of features is called a smart contract, and it could be described as a daemon program (for people who are not aware of the terminology, this is a service program running in the background), which operations could be stored into the ledger storage and are cryptographically signed. So essentially, when we transfer tokens, we call this program and its API.
Let’s return to NFTs now. Essentially, NFT means non-fungible token and is a non-divisible asset by its logic. Every NFT has a unique ID similar to the standard tokens and could be transferred between owners. There is a slight difference that we can not divide them, and currently, the protocol does not support multiple owners of the same NFT. Additionally, unlike standard tokens, NFTs could be emitted only by manual intervention but not auto-generated by the protocol itself as rewards.
A more profound analysis of the described behavior could give us the insights that NFS was designed to replace the standard legal contract by enabling the parties to upload their deal’s metadata into the blockchain. And thus to probably avoid the use of notary or at least to digitalize their work.
But how does this transfer to digital arts and collectibles? Usually, digital art is a digital file in some format (most of the time, we speak about images, but this could be a whole game model into a video game, for example). And copying a digital file is one of the basic operations we are taught when using computers. And here comes the help from cryptography – we could easily calculate a hash of the file, generate a random id for it, and sign them from the issuer name. This way, an artist could upload their file multiple times and offer a unique NFT for every file copy.
In conclusion – NFTs’ way of working is quite promising. With some will coming from governments around the World, it could easily automize and speed up the performance of different legal frameworks. Additionally, it would increase the visibility and clarity of how they work. At the same time – unfortunately, the way use it, aka selling pictures of cats and game models, is a little bit speculative. Unfortunately, it inherits some of the disadvantages of traditional fungible tokens, especially the problem with the emission of new assets into the network.
Unfortunately, during the last two years, we saw quite a rise in the number of cybercrimes worldwide. Many attacks allegedly came from nation-state actors, and we observed much blame in the public media space supporting this statement. Life is indeed a challenge, and the strongest ones almost always win. Still, there is a subdue difference between being aggressive and attacking foreign countries and defending your interests and infrastructure.
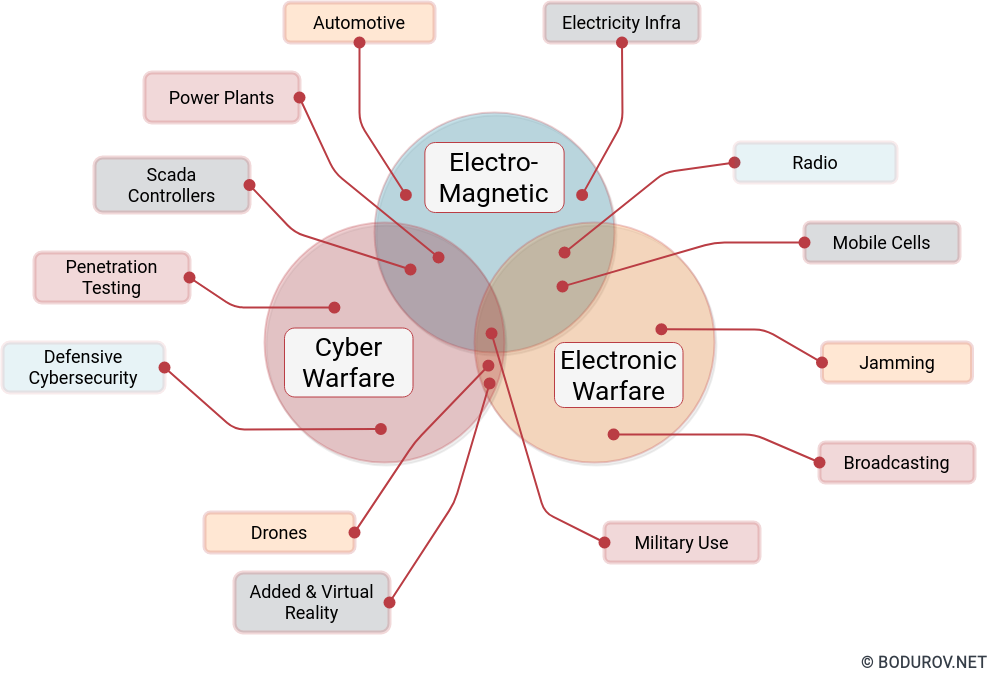
As a matter of fact, we could categorize the last couple of years as a series of standalone cyber battles, which could finally end in a fully-fledged cyberwar. And in such situations, some people start fantasizing about hiring hackers-privateers and starting a Cyber World War, where teams of the best hackers will fight each other. It sounds like an incredible plot for a sci-fi novel, but there are reasons why such actions could lead to disaster in reality:
On the diagram, you can see the standard military uses of electrical and communication equipment. Cyberwarfare privateers can use their skills to attack many targets without even going near the real battlefield
Global World: We live in a global village. The world is no more disconnected, and one crisis can quickly affect it. Check the COVID-19 situation, for instance. Despite its allegedly natural origin, it blocked the global economy and opened many old wounds. Now, believe me, if a worldwide cyberwar happens, we shall have much more complex problems, which could easily lead to conventional or even a nuclear, large-scale war.
Ethical Reasons: An old proverb states that one is to be able, another is to have the will, and the entirely different thing is to do it. Ethical hackers could start a fully-fledged cyberwar suitable for their businesses. However, I believe that cybersecurity must be more oriented to stopping criminals rather than achieving political agenda or starting conventional or nuclear wars.
Willingness: Most white hat cybersecurity specialists will not act of aggression for any sum of money. As patriots, they care for the well-being of their country; however, one thing is being a patriot, another is doing destructive actions versus another country or organization. At the same time, most hackers are criminals. Working for state actors will reveal their personalities and end them in jail. These statements reduce the number of individuals willing to work, such as hacker-privateers, to a tiny number.
In conclusion, cybersecurity and hacking are not similar to conventional armies. Sure, we can use the same terminology and ever do “war” games. But essentially, the whole sector is more identical to the standard private security companies, which defend infrastructure perimeters and fight crime. The role of pentesting companies is to test these defenses acting like criminals. Everything other than that should be categorized as cyber warfare and be forbidden.
The last article discussed the advantages and disadvantages of the Open Source software model. We even listed some uncomfortable truths regarding its economic viability and how it could be more expensive than many proprietary products. Despite being an Open Source zealot, I want to start with the statement that I still think proprietary software is sometimes better than Open Source ones. We can not compare my case with the average customer because I have spent the last 18 years working in IT – aka I want much more control over my system than the standard PC user. At the same time, when I can, I strongly avoid using proprietary software because I want to know what runs on my device or have the ability to review it if I wish. But let me list the good, the bad, and the ugly of using proprietary software:
The good
Legal responsibility: Wishing or not proprietary software vendors are obliged by law in most countries to take care of their customers and the data coming with the usage of the software. And yeah, many governments try defending their citizens and their data.
Better support: No one will pay for proprietary software if support is not included in the price. The difference to the Open Source vendors is that you receive some hours of first-level support with the cheapest plans, which is better than nothing.
Centralization: Having a more centralized way of management has advantages such as faster development speed, faster decision-making process, and fewer intrigues.
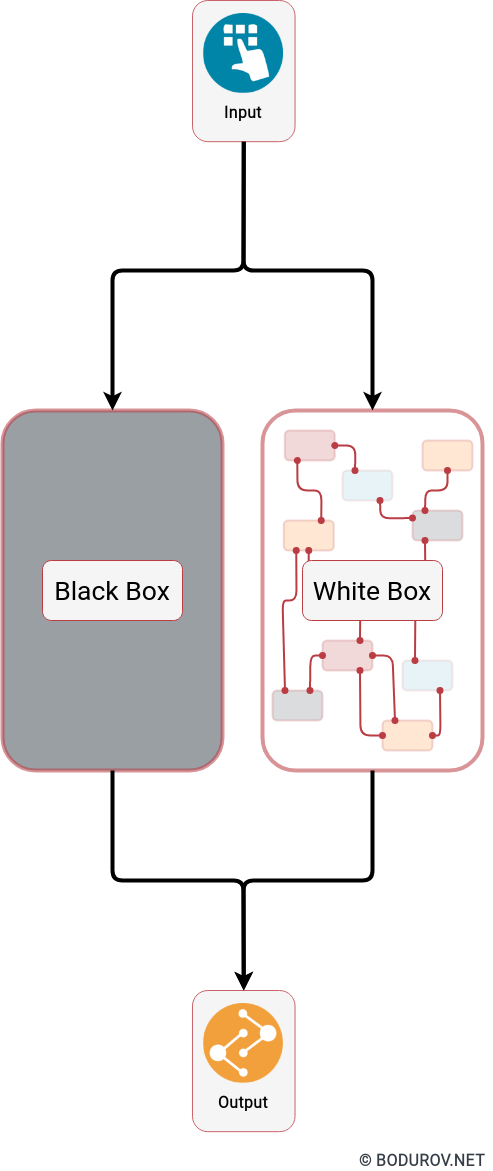
You can see a comparison between BlackBox and Whitebox software on the diagram. Open Source software is considered Whitebox because everyone can see and review its logic. On the other side, proprietary is considered as BlackBox because to analyze its behavior, analysts must use reverse engineering techniques
The bad
You should pay for it: One of the bad things regarding proprietary software is that people should pay for it. And the main problem is not the cost but businesswise; when you are using something you don’t have access to, you introduce a critical business dependency. What happens if suddenly this software vendor disappears?
Closed ecosystem: Decisions are made by the company’s owners producing the software. Customers usually do not have control or involvement in feature design and implementation.
More complicated collaboration: If two companies want to work together, they should sign a contract, and by signing this contract, they “decide” how their partnership will happen. By not having a ready-for-use framework, lawyers must review every agreement and make sure that both sides are happy with it.
The ugly
Sometimes less secure: Proprietary software has the same security problems as Open Source software. Many hackers are pretty adept in reverse engineering and finding security holes. Additionally, proprietary vendors must pay for security audits and could not rely on an ecosystem of hardcore software engineers to do that for them.
Lousy support for smaller customers: The bigger a software vendor becomes, the lousier its support becomes for its small customers. And this equals them to the Open Source software vendors without support for their free plans. And yeah, there is a reason for the number of jokes regarding the quality of support provided by given operating systems manufacturer :-).
Weaker legal defense: The bigger a software vendor becomes, the more legally powerful it is. And this leads to fewer opportunities for its small customers to search for justice. Usually, the side with the bigger pool of resources is the winning one in legal battles.
In conclusion, there is no significant difference between proprietary and Open Source software models. The only meaningful difference is that customers could legally claim stuff easily from smaller proprietary vendors. However, once the vendor becomes too big, they hire better lawyers, and experienced lawyers are pretty good at defending corporate interests. Other than that, the tradeoff for the end customer is first-level support versus free usage.
I want to start this post with the statement that I am a fierce supporter of Open Source, and all of my computers, servers, and smartphones are using different flavors of Linux. For the last ten years, I have used Windows ten times at most, all of this because some software vendors have been neglecting the Linux ecosystem for years. Other than that, I have no wish or necessity to touch Mac or Windows for anything rather than testing web or mobile apps.
At the same time, I want to strongly emphasize that Open Source as a model has its problems and that I believe no software development practice, Open Source or proprietary, is ideal. This post aims to list some of the advantages and disadvantages the Open Source model has. Despite its widely successful spell during the last 30 or more years, the model is somehow economically broken. But, let’s start with the lists:
The good
Open Source is almost free: Most open source projects provide free plans for casual users or tech-savvy customers by having an ecosystem. This way, a whole set of companies can build their business model based on these freemium plans and add value.
More openness: People working on open source projects must make an ecosystem. And people stay in any ecosystem only if the system is open to proposals and changes according to members’ needs. In another case, the ecosystem usually does not survive for long. Additionally, everyone can review the code and search for security holes.
Better collaboration: Legally speaking, if two organizations want to work together, they should sign a contract on every point they want to collaborate. Organizations already know how to work with the various Open Source licenses and do not need to reinvent the wheel for their specific case.
The bad
Lack of responsibility: Most Open Source software comes without any obligations for the authors. Whether there are security holes, bugs, or losses by using the software – authors are not responsible.
Too much decentralization: When a project becomes too popular, the lack of centralization increases politics and power struggles. By having multiple controlling bodies or boards of people governing the project, the number of interested parties increases and thus sometimes making the decision-making nightmare.
Lack of support: Some Open Source projects entirely lack technical or user support. Even if they offer support, the customer must pay too much money to get any meaningful help. The plans with the lower cost usually are not helpful enough.
On the diagram, you can see a standard crawler architecture diagram. Most of the products implementing this diagram would use Open Source components to speed up the development and lower the cost. They must live with the problems derived from using these components
The ugly
Sometimes less secure: Many projects do not have the proper set of resources to ensure their level of cybersecurity, despite being used by many people. A recent example of that is log4j – all major Java products use it, and at the same time, a big security hole was discovered a couple of weeks ago.
Complicated business model: Open Source is complex for monetization. Many products try surviving on donations or support. However, this monetization model does not scale as much as the proprietary one.
Legal mess: Usually, proprietary products step on Open Source ones to speed up the development time. This technique is used primarily in Start-Ups or consulting companies. However, this approach has its problems. What happens in a similar case such as log4j, where a security hole or a bug in one of your Open Source components leads to data leaks or financial losses? Who is responsible? By default, this is the user of the component, aka you.
In conclusion, Open Source is not for everyone. It could be more secure or with better support, but only if the code comes from a reputable software vendor. In all other cases, the user is left on its own to handle their security and support. Another question is whether the alternative (using only proprietary software) is better, but I will analyze this in another article.
With over 18 years of experience working in the Information Technology and Computer Science field, I have wondered how information can affect us as human beings and our brains. During the years, I invested a reasonable amount of time reading different brain models and how they interact with information. Unfortunately, no model measures the level of stress and distress information could put on our bodies. This article aims first to give a simple explanation of what the Internet is and how it could be connected to human brains and second to provide a sample formula of how information coming from different sources could affect our health.
This work uses some terminology coming from the works written by the following authors – Norbert Wiener, Freeman Dyson, David Bohm, F. David Peat, Peter Senge, John Polkinghorne, Edmund Bourne, Marcello Vitali Rosati, and Fredmund Malik. The ideas from these works helped me prepare this article and clear out my understanding of how the brain and information are supposed to work. I would suggest every specialist in Artificial Intelligence and Machine Learning read their works to better understand our reality and how it is supposed to function.
But let’s start with a couple of physics-based definitions:
Continuum: The traditional mathematical model of quantum space usually involves matter and energy. As some of the listed authors state, the next step is to add the information into the model and finally get a unified model consisting of matter, energy, and information.
Information: However, an excellent question arises – what is a piece of information? During the years, I read multiple definitions of the information, and it seems the scientific community can not decide which one must be the canonical one.
Entropy: For this article, I shall use two of the definitions of information based on entropy – first, the definition provided by the standard quantum space-based model, where the entropy shows the amount of energy in a given system and second the one supplied by Claude Shannon, which could measure the amount of information transmitted in communication. Most researchers consider information entropy and quantum space-based entropy directly linked to the same concept, while others argue that they are distinct. Both expressions are mathematically similar. Additionally, we could theorize that the information size can represent the amount of quantum energy going through our brains.
Dynamical system: In physics, a dynamical system is a particle or ensemble of particles whose state varies over time and thus obeys differential equations involving time derivatives. An analytical solution of such equations or their integration over time through computer simulation is used to predict the system’s future behavior.
In other words, we could use a dynamical system to describe the continuum, including all human brains and the Internet. At the same time, we could define the human brain and any computer-based device as a dynamical system (actually, a neural network is a type of dynamical system). And we could use entropy to “send and receive” information/quantum energy from the continuum to the human brain or a computer-based device.
Two additional definitions will help us to finish drawing the picture:
Passive information: By definition, we could define passive information as the entropy of a system, which is in a stable state and there is no additional energy, but if we put more energy into it, we expect the resulting entropy to be that one. Such systems without additional energy are newspapers, books, articles, computer hard drives, flash drives, etc.
Active information: On another side, if there is energy transfer into a given system, we could expect this transfer to come with the so-called quantum potential, and this potential contains information, which we could define as active information. Examples of such systems could be our brains reading books, watching videos, or listening to music. We could expect our brains to store information/energy the same way. Additionally, we could categorize most computer-based devices the same way.
After we have described all the needed definitions, let’s draw the whole picture using them as building blocks. We have the continuum and number of dynamical systems attached to it. Every system can receive and put energy/information into the continuum. Some systems are stable and only put energy/information in the continuum when other systems put some amount in them. Other systems are constantly in motion and emit and receive energy/information without breaks.
Many researchers categorize our brains and computers, such as reality engines – aka interpreters of quantum energy coming through them. However, these reality engines must be treated as emitters because human brains and computers emit energy via video, audio, motions, temperature, etc. Systems without additional energy are newspapers, books, articles, computer hard drives, flash drives, etc. could be called reality reflectors because they need a boost of energy to emit anything. In short, that way, we could connect the continuum to the virtual world “virtualized” by the Internet. But, let’s try to define some reality engines types:
Brain: Brains use natural information/energy and work by natural scientific laws. The reality presented by them abides by the physics rules, and anyone could not modify these rules.
Internet/Websites: The Internet mainly uses natural information/energy; however, the reality presented by the Internet could or could not abide by the natural laws. Many programming languages could define functions, which do not map to the rules defined by physics. Additionally, we could not know the quality of the information/energy stored on the Internet as passive information.
Video games: There is almost no limit to what kind of information/energy you can put into video games. The systems defined by the data in the video games usually could not occur in Nature. Additionally, video game engines often do not abide by the laws of physics. The primary purpose of almost all video games is to give the user the sense of easy and fast power, so instead of spending years of hard work to achieve something in the continuum, the user can do it in a couple of hours and feel fulfilled.
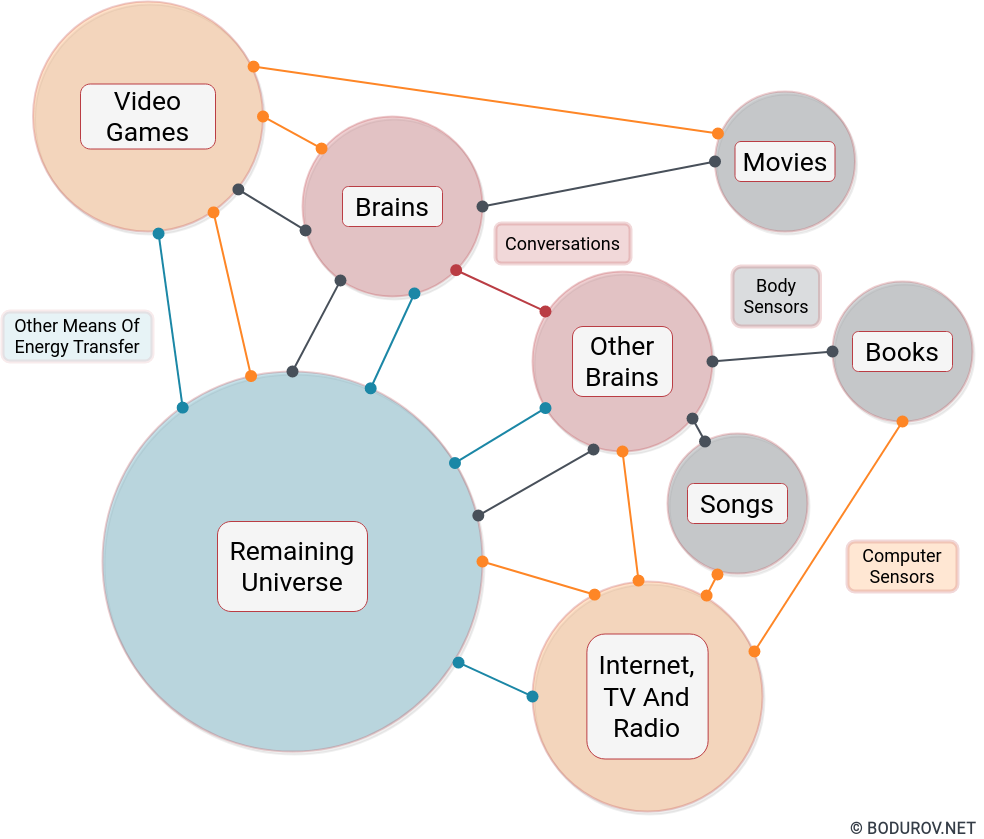
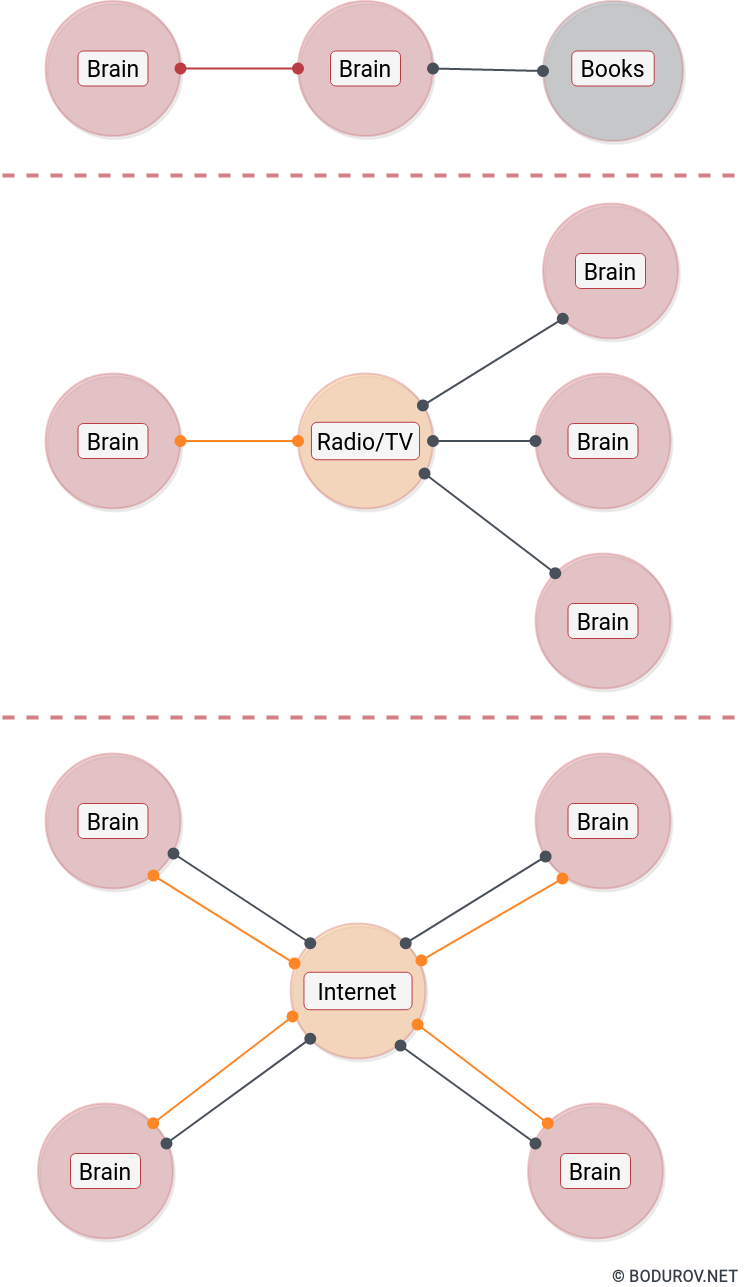
On the diagram you can see a sample dynamical system representing the energy transfer happening in the continuum. Most transfers happen thanks to a sensor activity. Whether there are other means of energy transfers rather than these using sensors, we do not know yet.
There is an interesting aspect of how the information/energy travels through the continuum. To reach from one reality engine to another, it naturally has stable paths. We could furthermore call these paths reality bridges and define them the following way:
Natural: By making a physical object (a passive or active information system), which travels the continuum using any transportation such as cars, trucks, planes, etc. The bandwidth depends on the capacity of the dynamical system.
Broad-casted: The information/energy travels using paths that are not bi-directional. So the energy is only transferred in one direction. However, multiple reality engines can receive this information/energy at the same time.
Peer to Peer: With the emergency of the Internet, now we have an even more connected topology, where one reality engine can receive and emit information/energy from/to another reality engine. Me writing this article is doing precisely that – emitting information/energy. My brain using the keyboard sends information/energy to my computer, which sends the information/energy furthermore to many computers.
After finishing the architecture presentation of our collection of dynamical systems connected to the continuum, let’s formulate two definitions used in the Information Technology field, which we could transfer to our collection of systems:
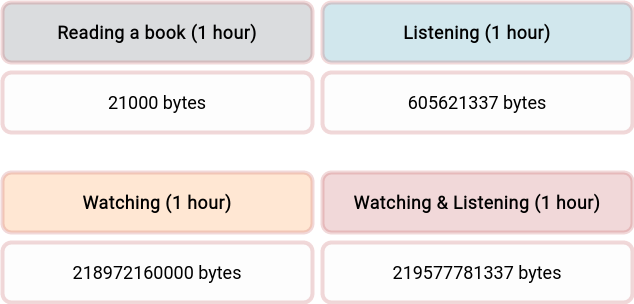
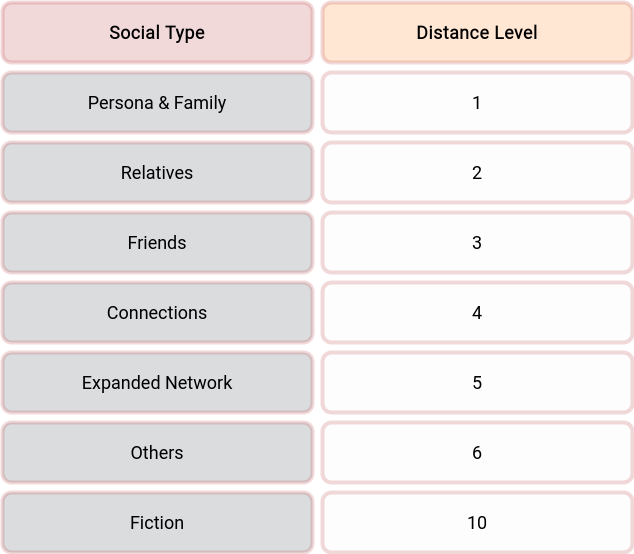
Bandwidth: The amount of information/energy that could be transferred for a time unit using a reality bridge. On the table, you can see the bandwidth which different reality bridges offer.
Latency: The delay of receiving the information/energy after the initial emit. We could expect that the longer information/energy travels, the more energy would be lost. However, the reality bridge would preserve the information.
After having all of these definitions and rules, let’s analyze in this current setup how information/energy could affect human health. We already perceived that the human brain may be working as a reality engine, and it looks like it is a dynamical system. At the same time, we can put and remove information/energy from this dynamical system. And every dynamical system has its capacity of states. Two questions arise – what happens if we keep pouring information/energy into the system but do not remove any from it, and could we expect to have some filter where the information/energy intensity could be decreased.
On the first question, in case of computer configuration, the computer will malfunction. In the case of the human brain, the short answer is – we don’t know. Based on the different theories I read, I could assume that pouring too much information into our brains could lead to psychological problems and psychiatric diseases. Another interesting fact related to our brains is that most psychological problems and psychiatric disorders could not be related to physical brain damage. The condition is entirely on a reality perception level, or we could assume it could be a problem with dynamical system capacity overload.
On the second question, in the case of a computer system, filters are already in place; however, these filters work too low level. On the so-called application level, things become more complex, and the computer needs human help. Regarding the brain, the situation is much more complicated. Based on our life experience, we could expect the intensity of the received energy to be based on how emotionally close to us is the reality engine emitting it. If it is our child and we receive negative news about it, we could expect the information to be with the highest intensity; however, if we receive negative information/energy for an unknown kid on the Internet or the TV, we could expect this to hit us with less power. Based on this observation, we could assume that there is an information/energy filter in our brains. It seems that this filter is based on the social distance (which is partially based on latency) to the reality engine emitting the information/energy.
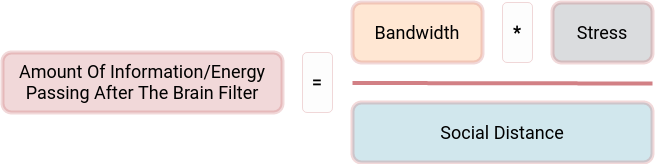
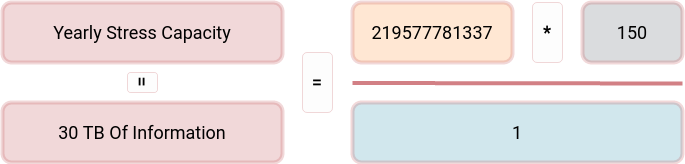
And finally, let’s combine all the upper statements into a single formula:
Bandwidth is the raw bandwidth of a 1-hour video and audio data chunk, calculated in bytes.
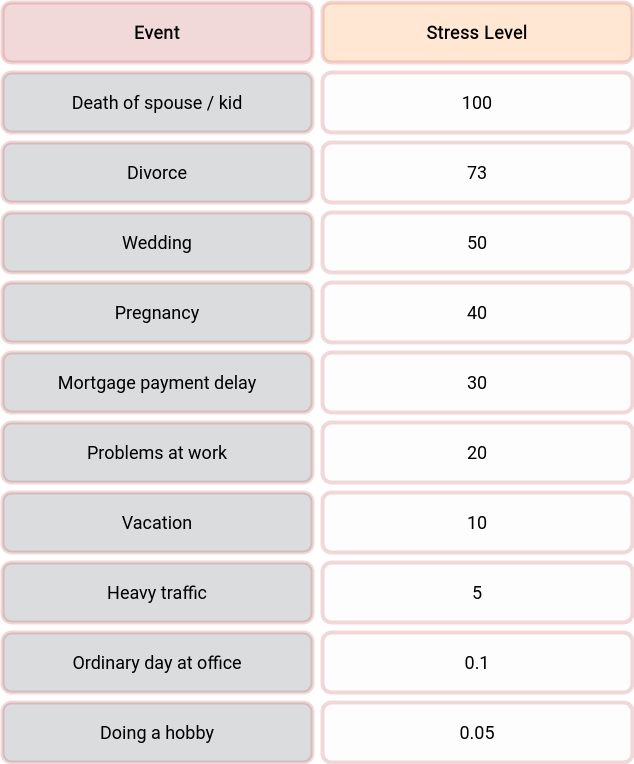
Stress is the level of stress which we could attach to the information/energy transfer. Check the different levels in the table, coming from the beautiful Edmund Bourne’s work on psychological problems and psychiatric disorders. I modified the table slightly to support more common daily events.
Social Distance is the social distance modifier, which we could find in its table. The modifier tells us that if we are experiencing the information/energy transfer from the first-person view, it will hit us the strongest, and if we hear that someone we don’t even know has a problem, then it will hit us ten times less.
According to Bourne’s book, the typical yearly amount of stress for a human being is around 150. Some people could endure higher levels, others less, but the median is around 150. We could calculate the number of information/energy an average human being can survive for the year using that data. After passing this limit, we could expect the person to start feeling the effects of distress. Another interesting assumption is that we could expect the level of stress to be reduced automatically over time. It seems our brains are designed to lose energy/information over a given time period and thus reduce the stress level to some predefined level.
If we play with the formula, we could see the following observations:
One could endure 1 hour and 30 minutes of information regarding the death of his/her kid per year
One could endure around 15 hours of the information regarding the death of someone unknown’s kid per year
One could take about 1500 hours of active office work per year
One could do his/her hobby about 3000 hours per year
Surprisingly the formula looks correct for most real-life social events. There are some edge cases with what happens if you read about your kid’s death in the newspaper. Will this information/energy hit you with less intensity than the video/audio equivalent? For sure, no. Probably, we could add a modifier based on the stress level per reality bridge type. However, the needed work to make the formula work for every edge case is far outside this article’s scope.
In conclusion, I would say that I do not pretend this work to be entirely scientifically correct. There are many scientific holes, which we could not prove adequately. Additionally, this article is my understanding of the listed authors’ works. I am not a physicist, nor a psychologist, and some of the nuances of the mathematical models used in these works could be too complicated for me to understand entirely.
However, for sure, the following questions need answers:
How does the Internet affect our brain?
How much information/energy can one put in his/her brain before burning out?
Could we relate the burnout symptoms to too much information poured into our brains?
Is the World moving faster or just the information/energy in it?
Must the amount of information/energy stored on the Internet be frightening to us?
Could getting this information/energy on a daily basis affect us in the long term?
Could the mindful and wellness techniques listed everywhere help us remove part of the information/energy from our brains?
Is the information/energy from our brains removed, or is there another mode of working where the active information is stored on standby?
And many more
I am convinced that some day, we shall receive answers to these questions, but with our current knowledge, the answer is – we don’t know.
In the last two parts of this series, we discussed our network protocol and the architecture of our body camera system. We shall discuss our backend recording and streamers service in this final part. After that, we shall present the budget we burnt for this MVP, and finally, we shall discuss why it did not work.
There are multiple server video streaming solutions across the market. Unfortunately, most of them require installing new desktop software or plugins. At the same time, we saw that no video storage format is codec agnostic and could support multiple frames using different codecs. All these weaknesses forced us to develop our storage format for our videos. After a reasonable amount of time of thinking about what would be the format we need for this kind of work, we formulated the following requirements:
Blazing fast append: We wanted to write down the incoming frames as fast as possible. Every slowdown of reindexing the frames would decrease performance and increase the cost.
File-based: Storing a significant amount of data into a database is the wrong approach for media-based files. So the file format had to be binary based. Because of the previous requirement, we had to skip the index. Every index recalculation would end up in a lousy performance.
To support telemetry: We did not stream only video and audio data, but we also streamed telemetry. There had to be a way to stream its frames as well. Plus, there were use cases in which the user of the body camera could want to stream only telemetry, but not video.
Websocket streaming: Since we can not support another streaming format, we decided that streaming from our server to the web browser clients in the headquarters will be based on WebSockets. To do this properly, we had to implement our video player.
Fortunately, if we analyze our network protocol, we can see the following characteristics which will fulfill the requirements:
Partitioning: Every network packet has a unique user id and date. And that is enough to determine the filename of the stream uniquely.
Counter: Every network packet has a unique counter value, and this value is attached to the date. At the beginning of every day, we moved the counter to zero. If we analyze further the logic of this counter, it could be used as an index key, by which we can sort by time the whole stream.
Supports telemetry: Our network protocol supports telemetry by default.
Supports WebSockets: We can reuse the same binary message we received from the Android device for WebSocket streaming. The message must be just encoded properly for WebSocket streaming.
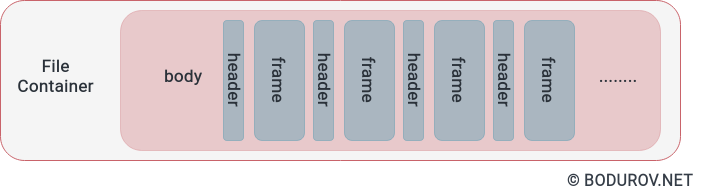
You can see the modified version of our frames container on the diagram. It follows the header:body format, where the header represents a metadata structure for the next frame. By iterating the whole file, we could index the metadata into our server’s memory
With the information from the previous bullets, we can define the following logic. We append every incoming packet to its corresponding file on the filesystem, similarly to what pcap is doing with the network packets. At the same time, another process is reading the file and building the index in memory of our service. And the service uses this index to restream the recorded network packets through web sockets to the web browser player.
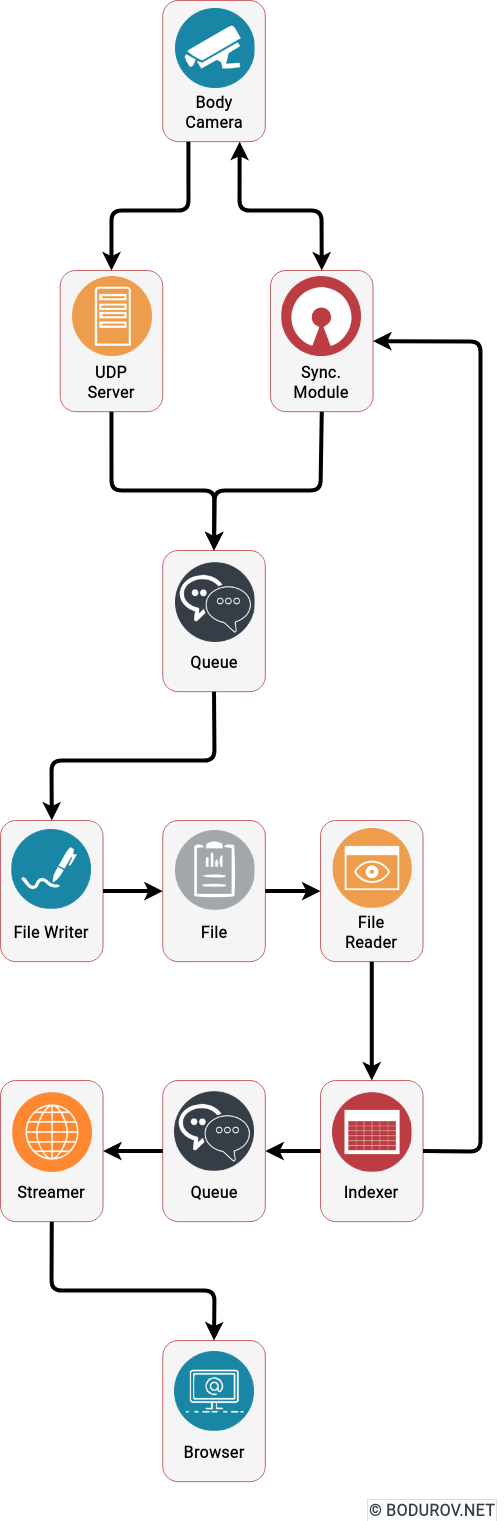
To implement the described logic, we decided to build the following system modules:
UDP server listener module: The idea of this module is to listen for UDP packets and reroute them to a concurrent queue. The FileWriter module later consumes this concurrent queue.
Concurrent queue module: Having in mind that we can have multiple process workers, instead of using mutexes or any other synchronization mechanisms, we decided to communicate using queues between the processes.
FileReader module: This module’s primary duty is to read the file packet by packet, using the already loaded index.
FileWriter module: The idea of this module is to take the packets from the queue and store them into the file. Partitioning per file per queue was implemented, and every file had a FileWriter process.
Indexer module: It reads the file and indexes the network packets into the memory. After that, it is used by the Streamer module to stream data.
Streamer module: This was a collection of processes that started by given offset and used the indexer module to send data to the WebSocket server.
Web browser player module: The module was used to decode the network packets coming from the WebSocket server and play video and telemetry data in the browser.
Synchronization module: The idea of this module was to provide a way for the synchronization of missing packets between the Android device and the streaming server. We used the index module to return a given user and date for which frames are missing.
One can easily modify the proposed architecture to support cloud deployment and high scalability by replacing the concurrent queues with message brokers and the local filesystem with GlusterFS.
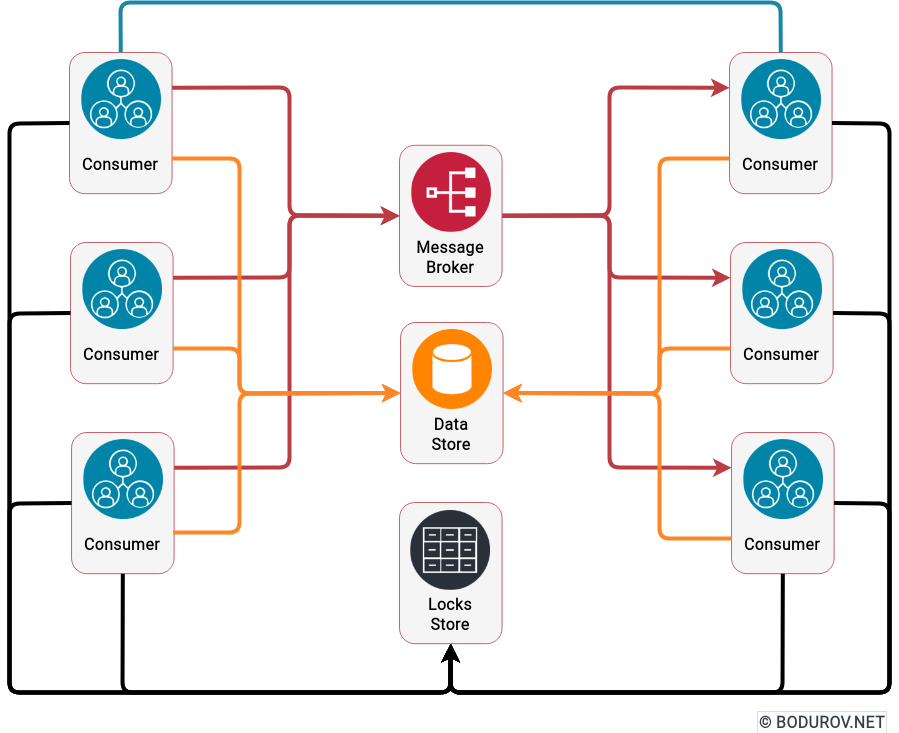
You can see a sample system architecture on the diagram describing the listed components. Arrows represent the data flows and how the data passed through the system
After we finished the technical details of the implementation, let’s discuss how much it cost for us to implement the MVP:
Budget:
Android device (200$): We decided to use a standard Redmi 3 device. It supported all the needed features, and it had an excellent battery.
Extended battery development (3000$): We developed two battery versions because the first one was not good enough, and our hardware vendor did not provide a quality job. We had to switch vendors, etc.
USB Camera (200$): Fortunately, we used an already produced board, so the price was relatively low. Still, we had to buy multiple cameras until we found the most suitable one.
3d printing (400$): 3d printing of multiple prototypes is expensive. And we had to try with various variations.
Camera mounts (30$): The camera mounts were already manufactured.
Software development (23000$): One developer spent a whole year working part-time on this project. He implemented the backend server and the mobile application for the Android device.
Hardware development (8000$): Our hardware guy spent a couple of months developing proper housing and an alternative battery unit for our Android device.
Business development (1500$): Fortunately, we did not spend a lot of money on business development.
So we managed to implement the technical MVP for a total cost of 36330$. We tried to sell it, and we failed brutally.
Why we failed
As a team without experience in developing hardware products, we made many errors. Fortunately, it was our first and last try at selling a hardware product. We took our lessons, which I shall list:
No business need: For every successful product, you need a local business need, with which you can test your idea and see whether you will have traction. Burgas is an almost crime-free city, so no need for such a system.
No hardware ecosystem: There is no ecosystem of electronic hardware manufacturers in Burgas. So you become dependent on people you do not know and even have never met.
No delivery pipelines: Making hardware depends on your components delivery pipelines. We did not have any established channels and no partners with such.
No investor: Hardware startups are not for bootstrapping. You need a good amount of money to hire the proper people and to make sure once you have MVP, you can buy a good amount of items. Hardware items supply can end, and after that, you have to redesign your solution.
Wrong paradigm: Hardware products do not scale so much as digital ones. It will help if you have a good global distribution network and marketing to do it successfully. Being in the 4th city by size in Bulgaria, with 200,000 people, did not help.
In conclusion, despite the problems, we managed to produce MVP, which is a piece of fantastic news. Unfortunately, we could never sell this MVP to anyone for the listed reasons. Looking at the good side of things, we learned what mistakes to avoid when penetrating a market. It helped us with our following products.