So, let me go back to cybersecurity. Sorry for the long, boring mathematical-based explanation in the last part, but if one wants to use a given tool, he/she must understand how it works and, more essentially, its limits. And I shall give you my list of concerns why believing in the current cybersecurity hype can be dangerous for you and your organization:
We must not compare a Machine Learning model to the human brain: We have no idea how the human brain works, and more especially how ideas creation and generalization work. Additionally, the pure power consumption of a machine learning model is times bigger than a human brain. Sure it is faster but much more expensive. The average power consumption of a typical adult is 100 Watts, and the brain consumes 20% of this, making the brain’s power consumption around 20 W. For comparison, Google’s DeepMind project uses a whole data center to achieve the same result, which a two-year-old kid does with 20 W.
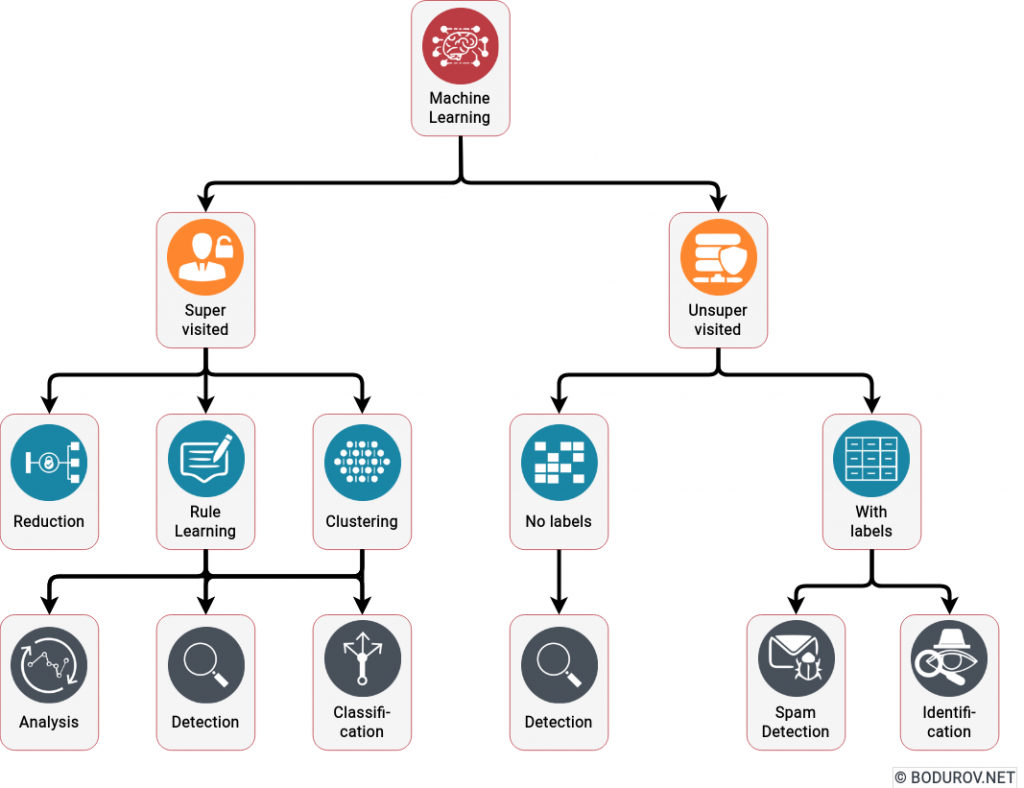
On the diagram, you can see what kind of problems Machine Learning algorithms can solve in the cybersecurity field. All of the activities listed in the last row are some form of categorization used for detection. No prevention is mentioned.
Machine learning is weak in generalization: The primary purpose of polynomial generation is to solve the so-named categorization problem. We have a set of objects with characteristics, and we want to put them in different categories. Machine learning is good at that. However, if we add a new category or dramatically change the set of objects, it fails miserably. In comparison, the human brain is excellent in generalization or, in social words – improvisation. If we transfer this to cybersecurity – ML is good in detection, but weak in prevention.
Machine Learning offers nothing new in Cybersecurity: For a long time, antivirus and anti-spam software have used rule engines to categorize whether the incoming file or email is malicious or not. Essentially, this method is just a simple categorization, where we mark the incoming data as harmful or not. All of the currently advertised AI-based cybersecurity platforms do that – instead of making the rule engine manually, they use Machine Learning to train their detection abilities.
In conclusion, cybersecurity Machine Learning models are good in detection but not in prevention. Marketing them as the panacea for all your cybersecurity problems could be harmful for organizations. A much better presentation of these methods is to call them another tool in the cybersecurity suite and use them appropriately. A good cybersecurity awareness course will undoubtedly increase your chances of prevention rather than the current level of Artificial Intelligence systems.
Lately, we see a trend in cybersecurity solutions advertising themselves as Artificial Intelligence systems, and they claim to detect and prevent your organization from cyber threats. Many people do not understand what stands behind modern Machine Learning methods and problems they can solve. And more importantly, that these methods do not provide a full range of tools to achieve the wet dream of every Machine Learning specialist – aka general Artificial Intelligence or, in other words – a perfect copy of the human brain.
But how Machine Learning works? Essentially, almost every algorithm in Machine Learning uses the following paradigms. First, we have a set of data, which we call training data. We divide this data into input and output data. The input data is the data our Machine Learning model will use to generate an output. We compare this generated output with the output of the training data and decide whether this result is good. During my learnings in Machine Learning, I was amazed how many training materials could not explain how we create these models. Many authors just started giving the readers mathematical formulas and even highly complex explanations comparing the models to the human brain. In this article, I am trying to provide a simple high-level description of how they work.
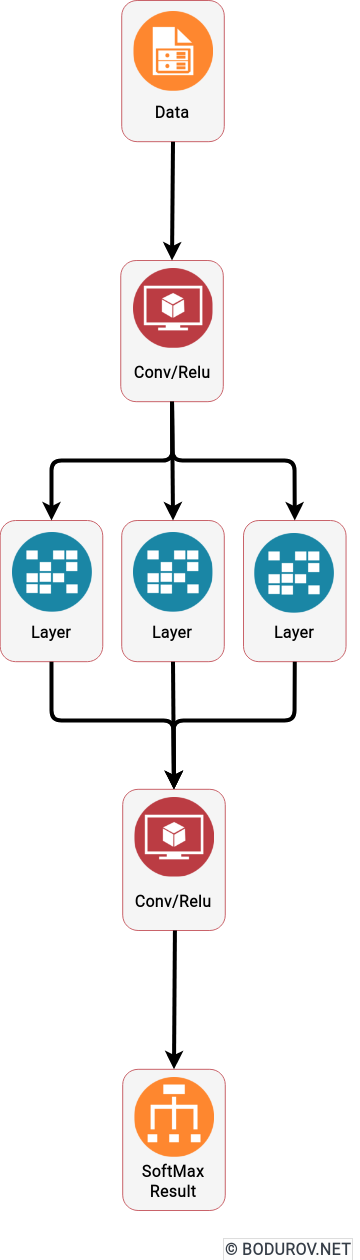
On the diagram you can see a standard Deep Learning Machine Learning model. The Conv/Relu and SoftMax parts are actually polynomials sending data from one algebraic space to another
So how do these Machine Learning algorithms do their job? A powerful mathematics branch is learning the properties of algebraic structures (in my university, it was called Abstract Algebra). The whole idea behind this branch is to define algebraic vector spaces, study their properties, and define operations over the created algebraic space. But let’s go back to Machine Learning, essentially our training data represents an algebraic space, and our input and output data is a set of vectors in that space. Luckily, some algebraic spaces can perform the standard polynomial operations, and we even can generate a polynomial rendering the input and output data. And voila, a Machine Learning model is, in many cases, a generated polynomial, which by given input data produces an output data similar to what we expect.
The modern Deep Learning approach is using a heavily modified version of this idea. In addition, it tries to train its models using mathematical analysis over the generated polynomial and, more essentially, its first derivative. And this method is not new. The only reason it has raised its usage lately is that NVidia managed to expose its GPU API to the host system via CUDA and make matrices calculation way faster than on the standard CPUs. And yeah, the definition of a matrix is a set of vectors. Surprisingly, the list of operations supported by a modern GPU is the same set used in Abstract Algebra.
In the next part, we shall discuss how these methods are used in Cybersecurity.
If we can use one sentence regarding the startup culture for the past decade, it will be Bubbles and Unicorns everywhere. These days every entrepreneur is trying to create the next unicorn and to fill its bubble with money. Unfortunately, looking at the facts, this approach is unsuccessful and usually leads to the startup’s failure.
But let’s analyze the definition of the unicorn in the startup culture – the unicorn is a startup with an evaluation of over 1 billion US dollars. Here is the essential point of our analysis. Evaluation is not the annual profit these companies are making. We could define evaluation as the “social” trust into a global brand, and we “evaluate” this “social” trust to 1 billion US dollars. Last year’s report showed that from 73 unicorn companies, only 6 had a positive net profit. And to make the situation even worse, 34 of these 73 unicorns had losses more significant than 30% of their revenue.
Having the previous paragraph in mind, we could easily deduce that without a proper IPO, these 34 unicorns would most probably end with a failure. Furthermore, the six profitable Unicorn startups (out of 73) did IPOs many years ago. No Unicorn startup among those announcing or doing an IPO since Zoom in August 2019 was profitable in 2019 (or 2020). The statistic suggests that the privately held Unicorns, which have yet to do IPOs, are primarily unprofitable. Thus, the record low profitability of startups is likely to get worse.
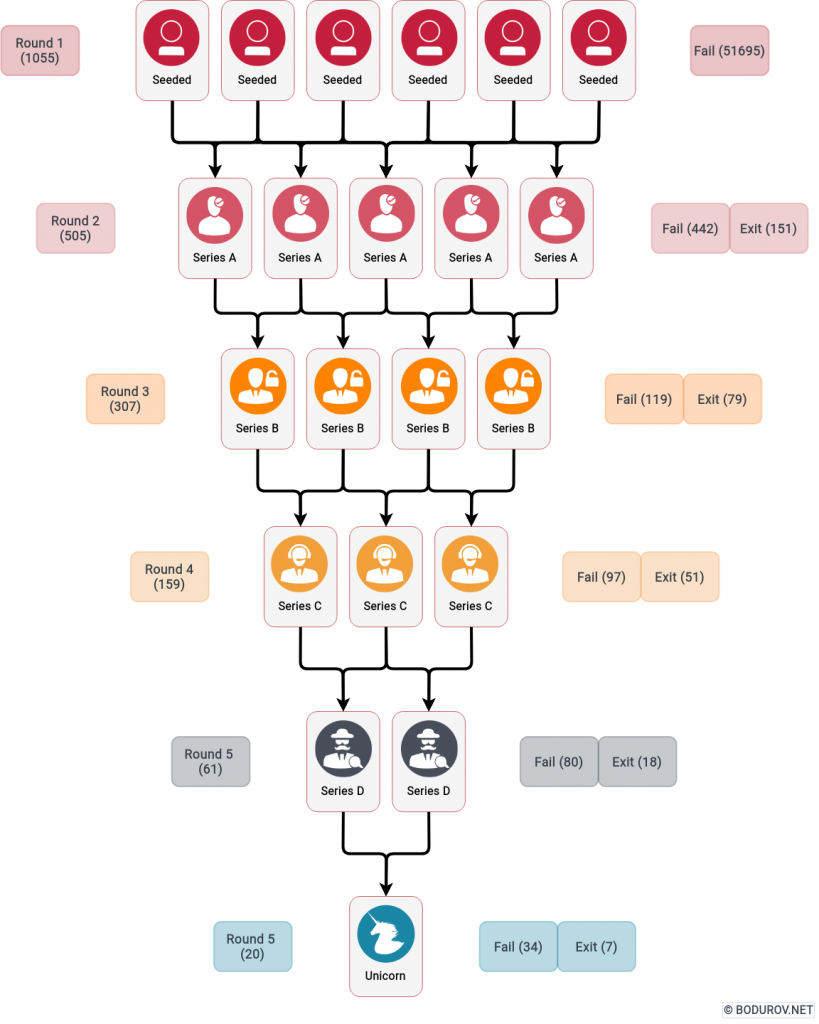
On the diagram, you can see a standard workflow of the making of a unicorn startup. In every round, more and more companies decide to exit, or they fail. Others manage to attract new funding and continue until they reach the dreamt status of the unicorn
And here is one exciting statement – every IPO company acts as an investment bank. It needs the IPO investors’ money to fund its activities. However, we need to ask ourselves whether this is a sustainable approach and whether we should mark unicorns as “successful” business ventures, considering that they do not operate on profit. And here is a sample list of reasons, marking unicorn as successful is a bad idea:
No net profit from their main business idea: Making not enough profit from their business idea means that the business idea is not viable. Evaluation of 1 billion US dollars does not mean that the assessment of the concept is so much.
Need of IPO to survive: Going into IPO mode means that the unicorn is now a public investment bank. In that sense, it starts acting as a bank, but not as a business venture. Another hint that the business idea was not profitable enough.
The considerable margin between evaluation and revenue: Sometimes, there is a significant margin between profit and revenue. It is essential to understand that evaluation is based on mathematical formulas, and as with every formula, the results can be set up for enormous evaluation. So, in short, a significant evaluation does not mean a successful business idea.
In conclusion, I think it is suitable for every entrepreneur and investor to ask themselves whether it is good to operate a business this way. Maybe a more prudent approach to doing business and ensuring the company has a minimized positive net profit will make the startup environment much better and less stressful.
Authors around the World publish tons of books on how to create your startup and how to scale it to a multi-billion company. People read these books, praise them and try mimicking the strategies written there. Even courses train you to present yourself in front of investors and get the next significant investment for your startup. All of these books give hope and motivation to the current and future generation of entrepreneurs.
Still, year after year, we see the same trend – 90% of the starting companies will fail until their 2nd year. Or in more human-readable wording – 90% of the new companies can not reach the sustainable revenue phase, and their bubble burst until their 2nd year. At the same time, 97% of the latest companies fail until their 5th year. This statistics is quite sad because it shows that all the courses and books on the World are not enough for your startup to succeed. You need experience and first point of view knowledge of how things are working and what is necessary for success.
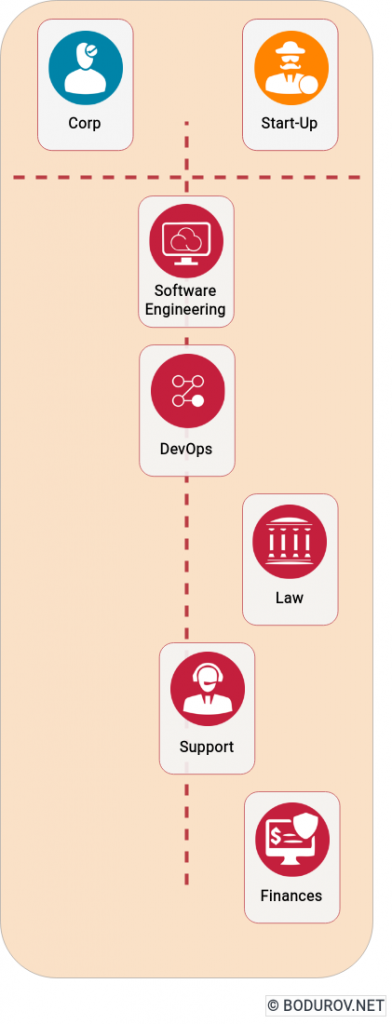
On the diagram, you can see a standard corporation versus startup skills distribution. Startups team members need to understand the business side much more than the regular corporation employee
Many people do not realize how difficult it is to create a startup. It would help if you had lots of experience to make it happen. 99% percent of the population on our planet do not have this experience, and to gain it, they need to fail. And to fail hard and often. Let’s analyze why 90% of the startups fail until their second year of running.
The average length of an IT project is between 18 and 24 months. If you do not manage to scale your product for this period, then, most probably, your business model does not work, and it will not scale at all.
The average person has some resources put aside for this period. If you are trying to make a bootstrapped business, this period is your lifeline to achieving any progress.
In case you manage to gain traction for your startup idea. Many people do not know how to scale it out and make this traction a sustainable business. One of the biggest problems is customer support after you manage to get the initial traction.
Let’s analyze the stats about startups’ failure. 90% of the startups fail until the second year. It directly says – you will need, on average, nine failures to pass the second year of startup life. If we multiply this number to 18 months (average lifetime of one IT project), then we receive 9 * 18 = 162 months or almost 14 years of working in startups to make one of them successful. That’s why most of the time, one startup needs at least two or three co-founders with enough experience in startups to scale.
In conclusion, making a startup is hard. It is not for everyone, and many people lost time and money trying to create one. Without the proper experience and coaching, the failure of startups will continue. From my personal experience working in startups, some of them, relatively underfunded; if you pass the second year, your chances of success improve dramatically. And yes, the SAS drop rate is, on average, around 94%.
Now, as we can see, attackers can penetrate all of the hardware network devices we reviewed. How easily it depends on how do you set up your cybersecurity and patch policy.
It is clear that despite your best effort, you must not blindly trust your routers and switches. Lack of trust is precisely the paradigm behind the zero trust model. At the same time, to make attackers’ life harder, it is important to mention three types of defensive cybersecurity tools, which can help you increase your defenses and trust in your local network.
Until the end of this article, I shall describe them. As a final, I shall give a sample budget for both router and switch devices. Both of them will use open-source software. Usually, they receive software updates quite often and can offer your a good level of security.
Firewalls
A firewall is a network security service that monitors incoming and outgoing network traffic and decides whether to allow or block specific traffic based on a defined set of security rules.
Firewalls have been the first line of defense in network security for over 25 years. They establish a barrier between secured and controlled internal networks that you can trust and untrusted outside networks, such as the Internet.
Usually, in the case of home networks, this service is deployed in your hardware router. The last sentence means that the attacker will expose your entire local network to the Internet in case of router penetration.
Intrusion Detection/Prevention
An intrusion prevention system (IPS) is a form of network security that detects and prevents identified threats. Intrusion prevention systems continuously monitor your network, looking for possible malicious incidents and capturing information about them. The IPS reports these events to system administrators and takes preventative action, such as closing access points and configuring firewalls to prevent future attacks.
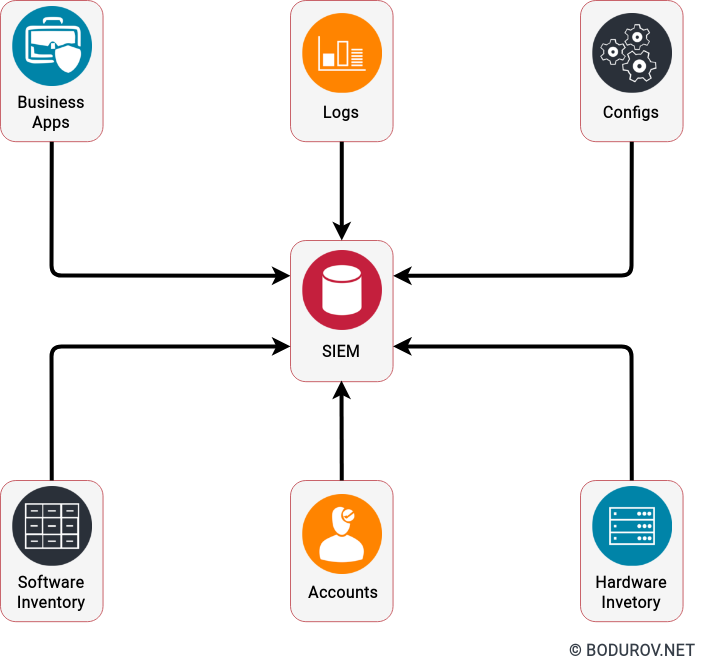
An intrusion detection system (IDS) is a device or software application that monitors a network or systems for malicious activity or policy violations. Any intrusion activity or breach is typically reported either to an administrator or collected centrally using a security information and event management (SIEM) system. A SIEM system combines outputs from multiple sources and uses alarm filtering techniques to distinguish malicious activity from false alarms.
At home routers, intrusion prevention systems can be deployed on the router device and inspect all the incoming network packets from the Internet. On the other hand, an intrusion detection system is deployed on all the hardware devices connected to your local network. In simpler words, prevention systems monitor your incoming traffic, and detection systems monitor your local network for anomalies.
On the diagram, you can see a standard SIEM system. The idea of the system is to aggregate all of your logs and data and offer analytics to your security engineers
Group Policy
Group Policies, in part, control what users can and cannot do on a computer system. For example, a Group Policy can enforce a password complexity policy that prevents users from choosing an overly simple password. Other examples include allowing or preventing unidentified users from remote computers to connect to a network share or block/restrict specific folders. A set of such configurations is called a Group Policy Object (GPO).
Now, group policies can be a powerful instrument for system administrators to define how the organization computers act to different security threats. Unfortunately, Group Policy settings are enforced voluntarily by the targeted applications. In many cases, this merely consists of disabling the user interface for a particular function of accessing it. Alternatively, a malicious user can modify or interfere with the application to not successfully read its Group Policy settings, thus enforcing potentially lower security defaults or even returning arbitrary values.
For home-based local networks, the usage of group policies is usually limited. Still, I would advise system administrators of small teams to think carefully, how to add group policies to their remote office deployments. In combination with VPN, Group Policies can add much value to your cybersecurity workflow.
Budget
As I promised at the beginning of this series, I shall give a sample security budget for every topic we discuss. Again I will tailor the budget to small teams with an underfunded budget for cybersecurity defenses.
Router (180$): I would go for Pfsense or IPFire based hardware appliances. Both provide reasonable protections, even though the first is based on FreeBSD and the second is a Linux distribution. Both have state-of-the-art firewalls, and both support Snort and Suricata, which are the best intrusion prevention systems. Additionally, they have Syslog support so that the router can become a part of an intrusion detection system.
Switch (150$): SwitchBlox Rugged is a good option here. It is a little bit more expensive than the standard network switches. However, it comes with an open-source networking operating system and can work in harsh environments. Two switches can be stacked together.
SIEM System (0$): MozDef is a SIEM system developed by Mozilla. It is open-source and supports all the necessary features for SIEM systems.
Group Policy Server (150$): We can order PC Engine’s apu4d4 unit and install on top of it Univention Corporate Server. With it, we can create policies for Ubuntu and Windows-based computers.
With a total budget of around 480$, we achieved a pretty good level of security. Still, a determined attacker can penetrate this setup, but it will take him more time and resources. The switch is optional, but it will help if you want improved security and choose to have a WiFi network for guests only.
In conclusion, setting up a network perimeter can be done effectively on a budget. Still, it is essential to note that the budget does not include the human hours needed to set up the equipment and your local network.