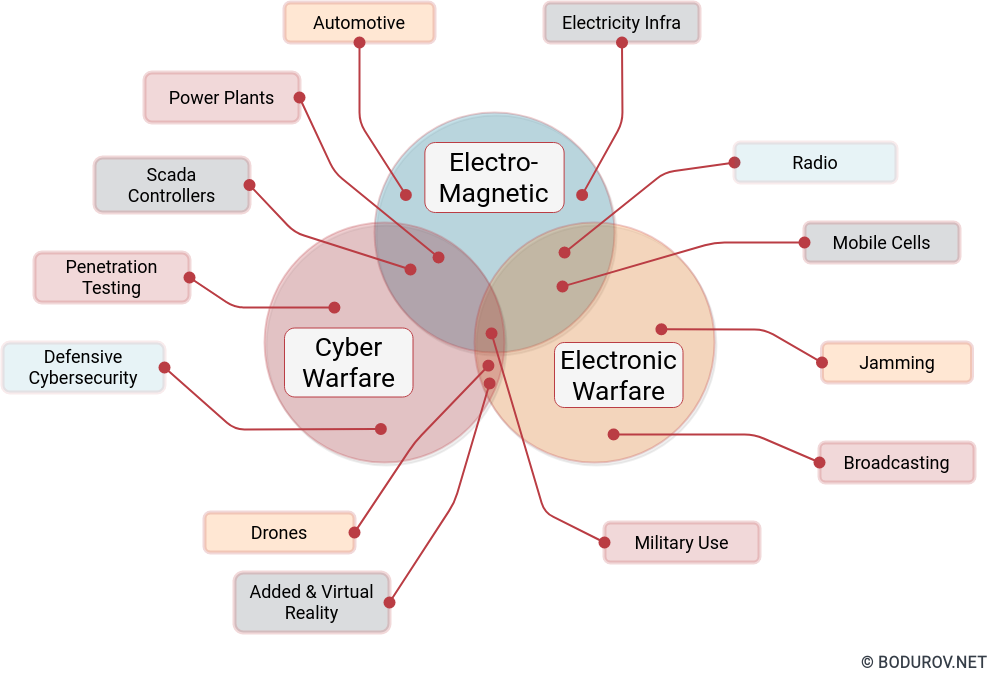
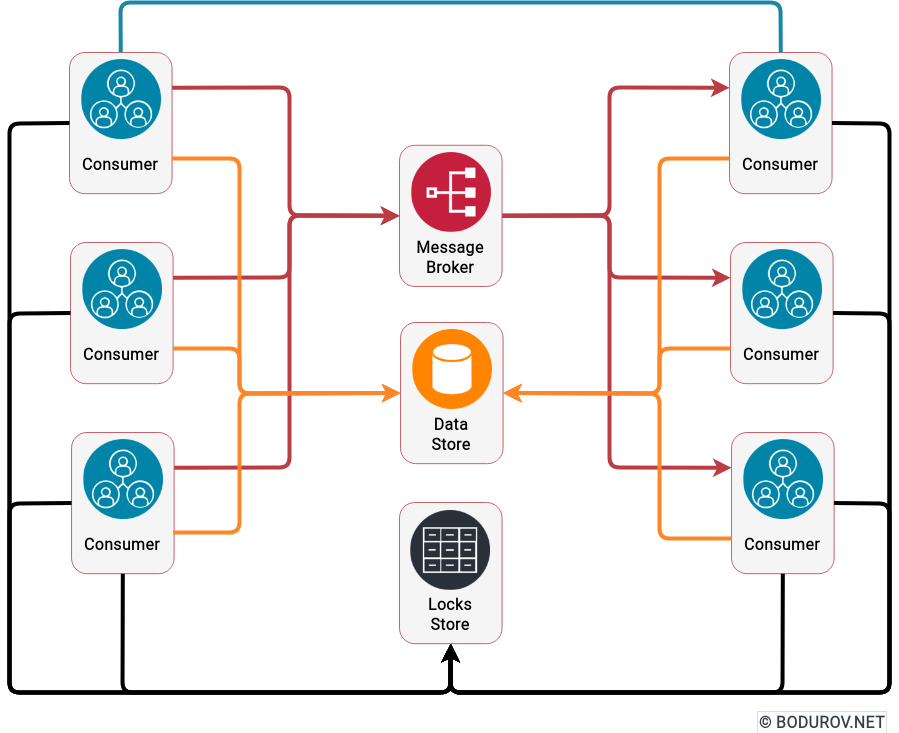
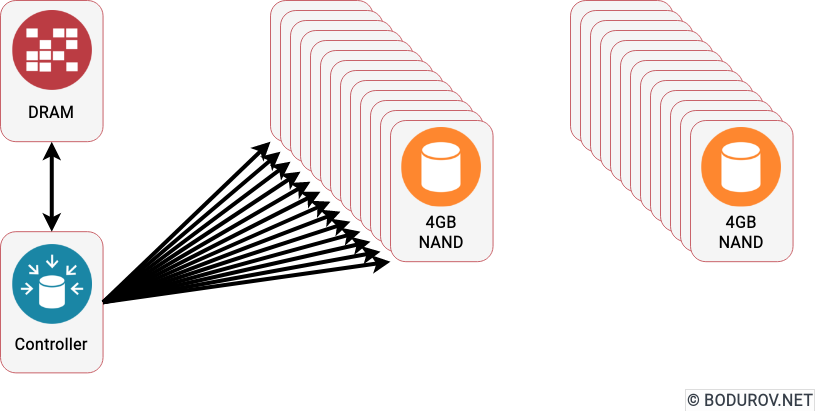
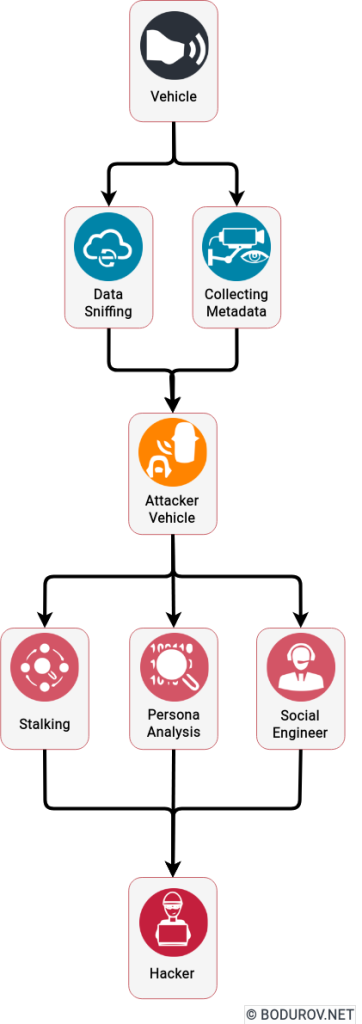
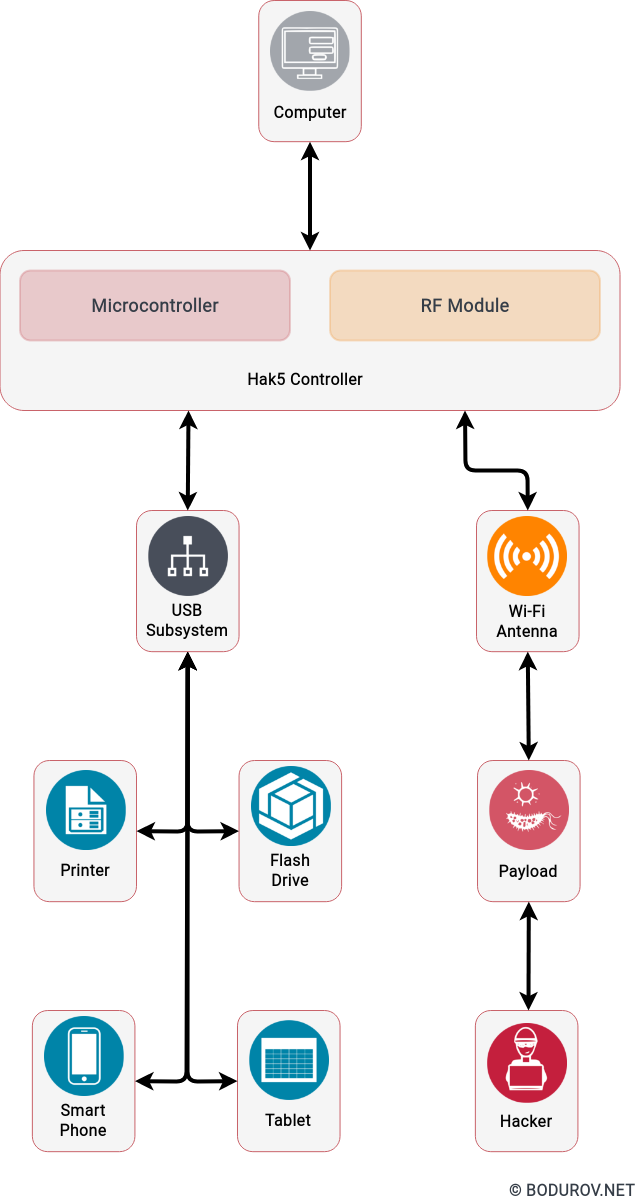
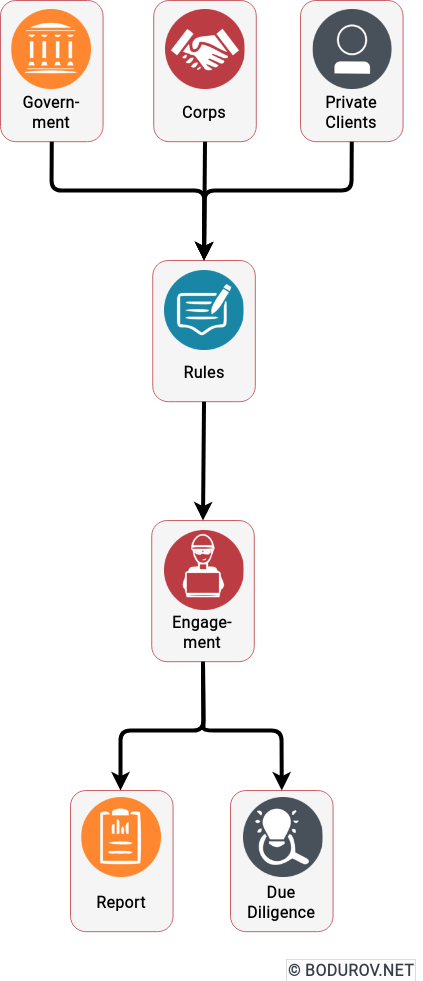
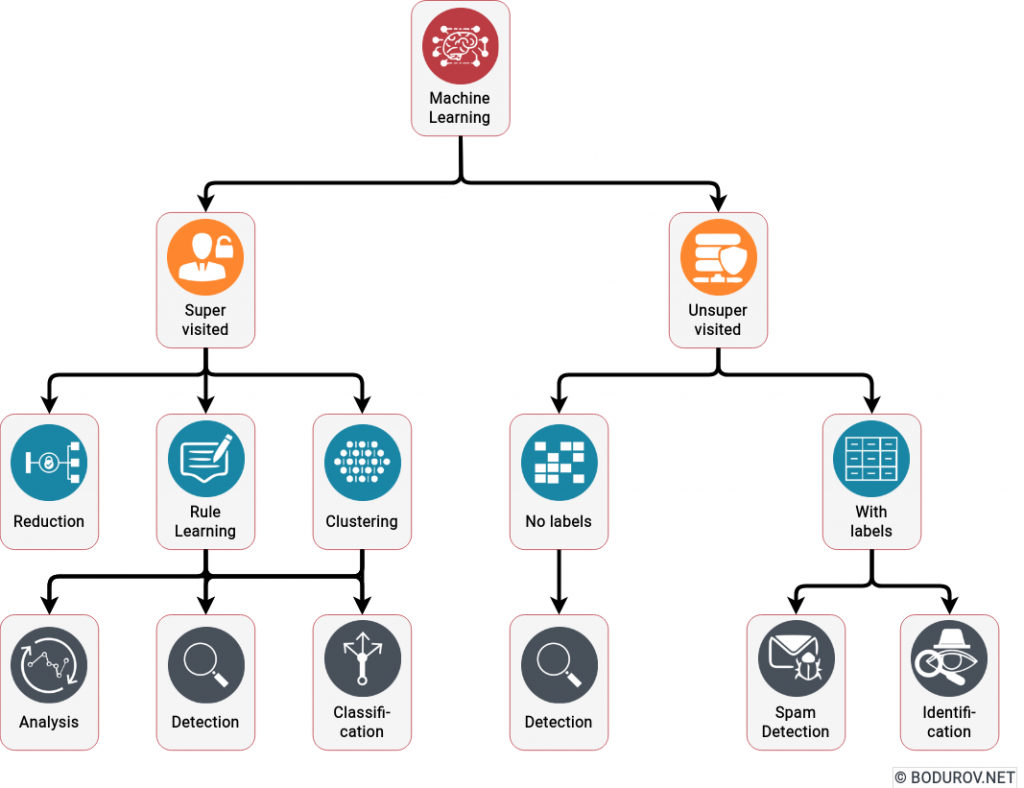
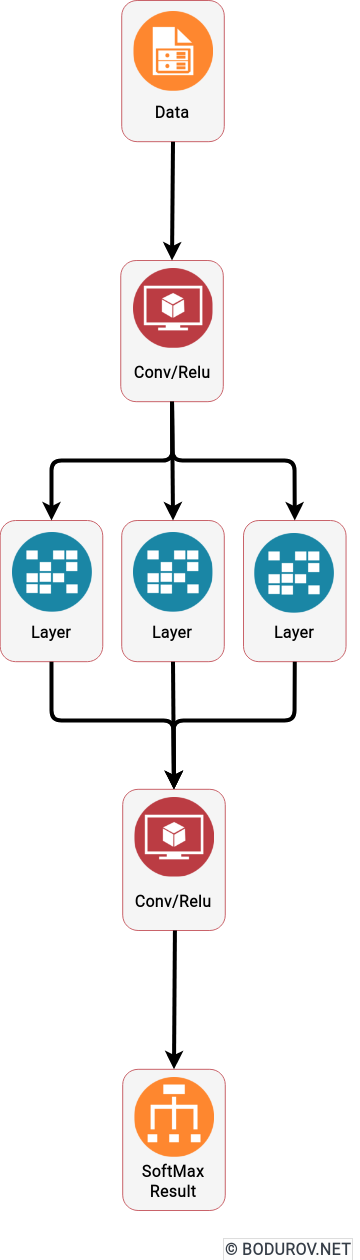
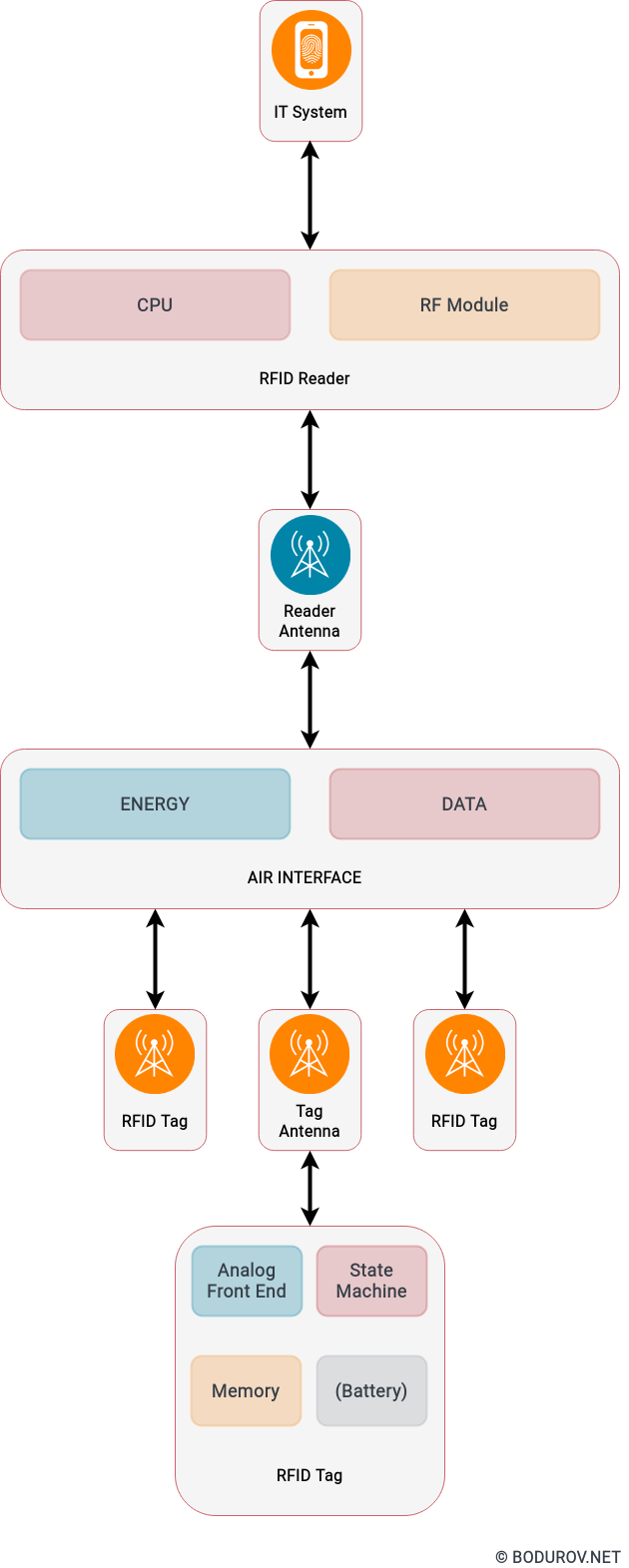
I started wondering how people can prepare themselves for such times, given the recent events. Military clashes are happening in the real world and the cyber one in modern times. The are many parallels between defending assets in both of these worlds. In this article, I shall try listing the different approaches one could use to harden their defenses. At the same time, I shall try giving a clear picture of the target goals of the defenders.
So what is the ultimate goal of every defender? By default, it is to make the cost of the attack too high, and this way to diminish the gains of that attack. This kind of narrative is often seen in many books focused on the defensive side of cybersecurity. It is important to note that sometimes, people attack other people for personal reasons or even because of emotion. In these cases, attackers usually do not care how much it will cost them to perform the attack. As a defender, we should consider these reasons during the design phase of our defense.
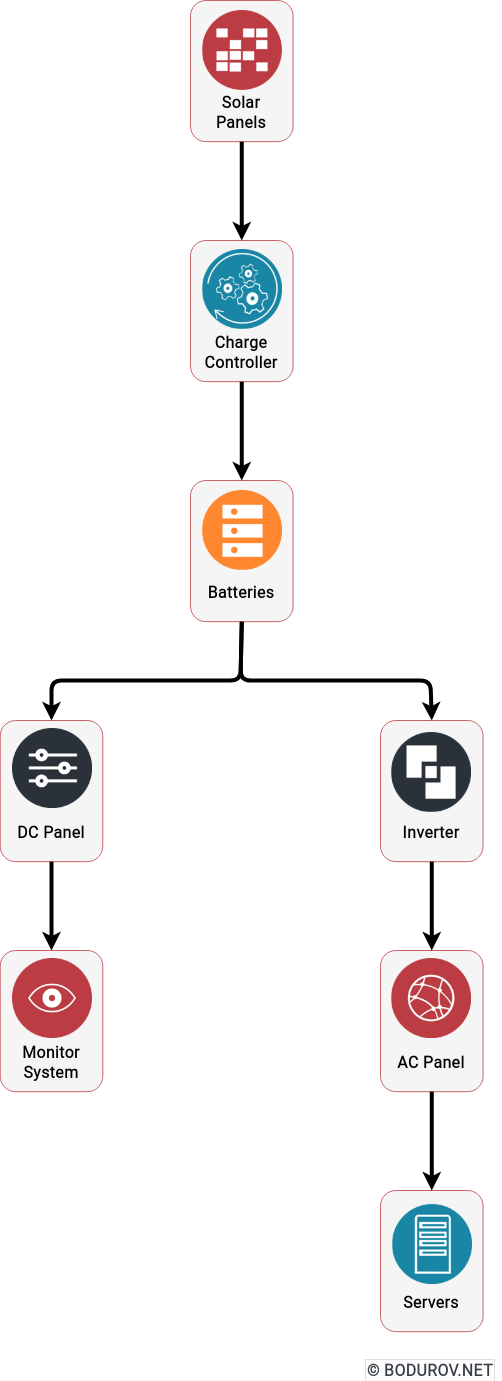
There is one exciting proverb regarding the importance of preparation – more sweat in training, less blood in the fight. If we transfer this to the realm of cyber security – the more efforts we put into preparing the infrastructure, the less likely it is to be penetrated. So how we can prepare ourselves for an attack:
- Buy quality equipment: Your equipment shouldn’t be the most expensive or cheapest. You need gear that can do the job and have a lifespan of at least five years. It is a good idea to buy multiple pieces, so you have hot swaps in case of failure. Items in the middle price range usually are good candidates.
- Plan and train: There is little sense in having great gear without using it. Regular training sharpens the skills and decreases the reaction time during the use of the equipment. At the same time, testing the items help check their limits and allows the designer to prepare a better defense. In the realm of cybersecurity, we could do regular red/blue team games where the red team will try to penetrate the infrastructure, and the blue team will defend it.
- Be realistic: If your attacker has much more resources (money and time) than you, they will penetrate you. There is no great sense in making sure your electronic infrastructure survives an EMP wave coming after a detonation of a nuclear warhead. At the same time, it makes excellent sense to make sure your data is backed up into a protected vault and that you have replacement units if such an event happens.
- Hack and Slash: Don’t be afraid to modify your equipment if it does not suit your needs. Many security units prefer buying cheaper equipment and rigging it for double or triple purposes. Play around with your gear, and don’t be afraid of breaking it. Sometimes you can find real gems by doing that.
In conclusion, preparation for any defense activity comes with a lot of research. The primary goal of every defender is to increase the cost of attack. The higher the price is, the less motivated the attacker will be. Often the resources of both sides are asymmetric, and thus, some defenders must think such as guerilla fighters or even as Start-Up owners. They have to squeeze the last piece of efficiency provided by their infrastructure.